
Découvrir et questionner les IA génératives avec Compar:IA
Compar:IA, c'est quoi ?
Le service Compar:IA a été lancé en octobre 2024 par le Ministère de la Culture et la Direction Interministérielle pour le Numérique.
- Les données de préférences issues des évaluations par les utilisateurs servent à améliorer les modèles de langage (LLM) avec des données d'usage francophones. Elles réduisent ainsi les différents biais liés à la prédominance de l'anglais.
- En proposant de comparer les réponses générées par différents modèles ainsi que leur impact environnemental, Compar:IA favorise le développement d'un esprit critique face à ce qu'il convient de nommer au pluriel : les Intelligences artificielles génératives.
 Comment l'utiliser ?
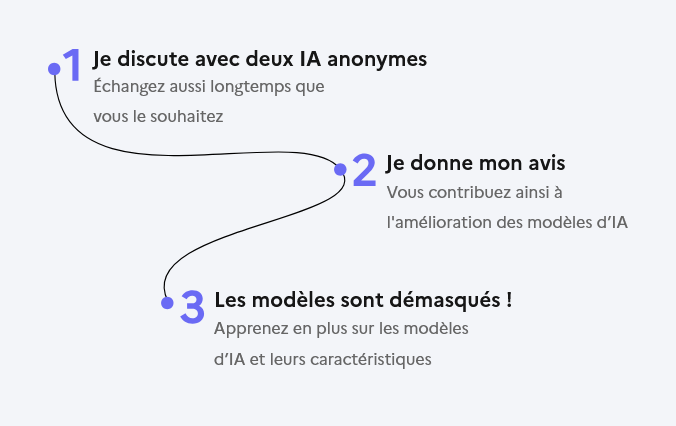
Comment l'utiliser ?
Sur la page d'accueil, le protocole d'usage est clairement indiqué :
- Tester avec deux IA en parallèle
- Donner son avis sur les réponses
- Prendre connaissance des caractéristiques de chacun des modèles
Si nous l'utilisons gratuitement avec nos élèves, il faut en contrepartie faire un retour d'expérience de qualité.
Le test
Une fois acceptées les modalités d'utilisation, un avertissement prévient de la nécessité de vérifier les informations communiquées. Il faut aussi expliquer aux élèves l'interdiction de communiquer des informations personnelles et les prévenir que tous les mésusages de l'Internet sont tracés.

Un champ invite à écrire le premier prompt, ou message.
Contrairement à ce qu'indique l'écran d'accueil, il n'est pas obligatoire de comparer deux modèles anonymes choisis de façon aléatoire. On peut directement choisir lesquels on souhaite comparer, en cliquant sur le bouton Modèles aléatoires.
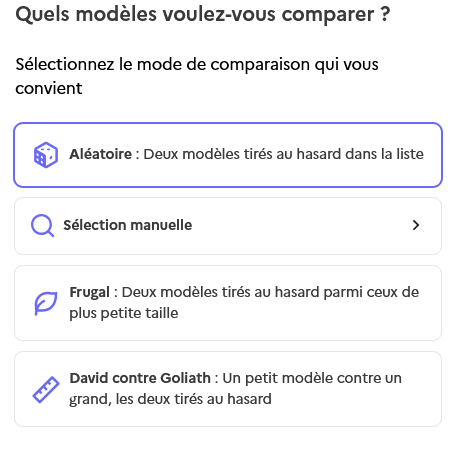
Pour une découverte, le choix aléatoire est une bonne option.
La première requête correspond à un sujet récemment étudié en classe, sur lequel les élèves disposent déjà de connaissances. On observe la rédaction en direct des réponses de l'un et de l'autre modèle.
La génération est-elle aussi rapide ?
Est-elle de même longueur ? L'une est-elle plus détaillée, mieux structurée ?
Le contenu est-il approfondi ou superficiel ? Son analyse révèle-t-elle des erreurs ou approximations ?
Les élèves peuvent voter pour manifester leur contentement.
Il est possible de poursuivre l'échange avec les deux modèles pour tester leurs capacités à adapter leurs propositions en fonction de nos demandes, mais aussi celle à garder le fil de la discussion : la vitesse de décrochage indique les limites des intelligences artificielles et différencie leur traitement des données des compétences multiples de nos interactions humaines.
On observe la présence ou l'absence de mention des sources. L'envoi systématique d'une question complémentaire "Quelles sont les sources d'information ?" et l'analyse des réponses questionne sur la nature des informations. C'est un point que l'on abordera systématiquement pour la suite du travail sur les IA.
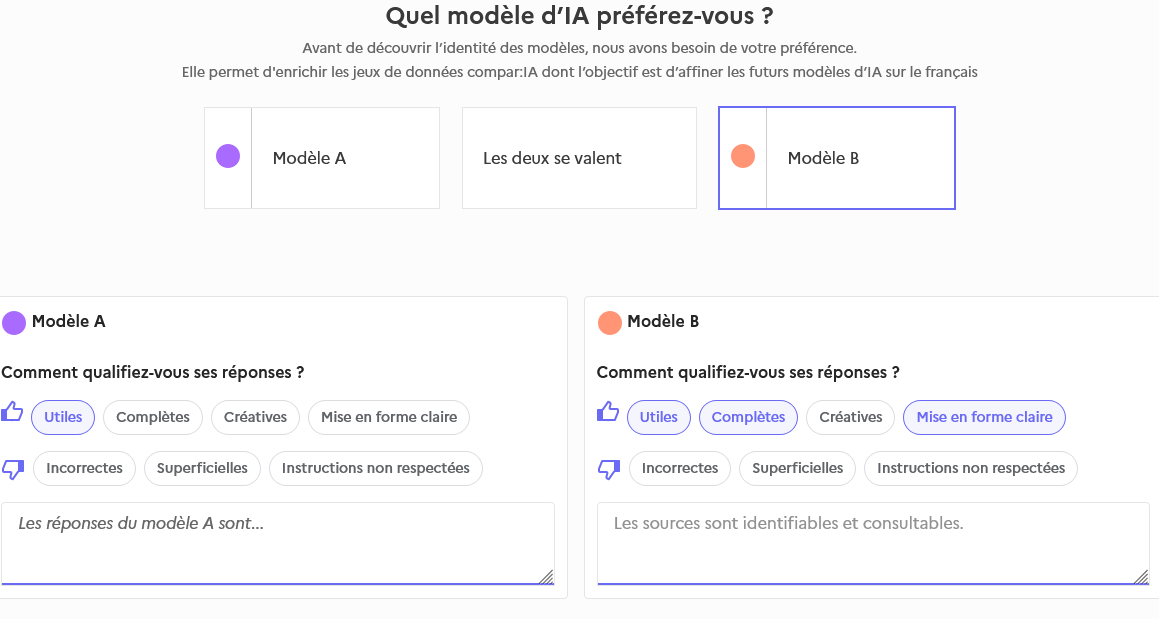
L'évaluation
En passant à la révélation des modèles, c'est un classement préférentiel, puis une évaluation de chacun des modèles qui sont demandés. La collecte de ces éléments est monétisable. Elle servira à l'amélioration des modèles en fonction du public francophone. Elle finance le service Compar:IA.
Cette étape d'évaluation formalise le travail d'analyse et critique des productions. Il induit une prise de distance face aux générations par IA : le réflexe du pas-de-côté propre à toute éducation aux médias.
La révélation
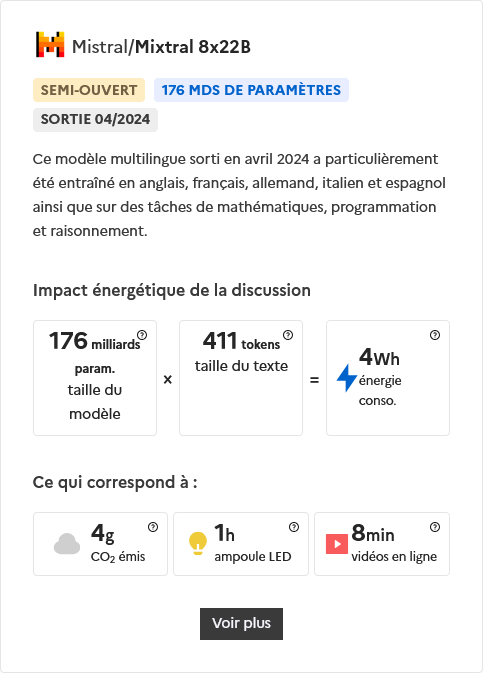 Outre la présentation des modèles, la révélation dévoile leurs tailles, exprimées en milliards de paramètres. La notion d'apprentissage et de pré-entraînement est inhérente au fonctionnement des IA génératives, comme l'indique l'acronyme du célèbre ChatGPT, premier paru en 2022. Cet apprentissage soulève la question des sources et de la date de publication des informations. Le questionnement de l'obsolescence des données est incontournable, tant dans la perspective d'une recherche scientifique ou technologique que dans celle de l'usage des IA pour s'informer sur l'actualité. Une IA brute fonctionne sur un corpus dont il est souvent difficile de connaître la nature exacte : questions de droits d'auteur et de secret commercial...
Outre la présentation des modèles, la révélation dévoile leurs tailles, exprimées en milliards de paramètres. La notion d'apprentissage et de pré-entraînement est inhérente au fonctionnement des IA génératives, comme l'indique l'acronyme du célèbre ChatGPT, premier paru en 2022. Cet apprentissage soulève la question des sources et de la date de publication des informations. Le questionnement de l'obsolescence des données est incontournable, tant dans la perspective d'une recherche scientifique ou technologique que dans celle de l'usage des IA pour s'informer sur l'actualité. Une IA brute fonctionne sur un corpus dont il est souvent difficile de connaître la nature exacte : questions de droits d'auteur et de secret commercial...
Il faut implémenter des systèmes aux IA pour parvenir à une Génération augmentée par récupération (RAG), capable de citer au moins une partie des sources. Il faut d'autres briques technologiques, les agents conversationnels, pour d'accéder à l'actualité.
Certains des modèles proposés par Compar:IA sont ainsi en mesure de révéler certaines de leurs sources à la demande. D'autres ne le feront pas. Si c'est le cas, il conviendra de questionner le choix des sources effectué par l'IA, notamment sur les questions d'actualité, en référence au contrat de lecture accepté tacitement par le lecteur d'un média dont il accepte la ligne éditoriale en le choisissant. Connaître ses sources d'informations et les sélectionner en conscience est une compétence essentielle.
Le nombre de tokens (jetons textuels) correspond à la taille du texte généré. Il s'agit d'unités d'à peu près quatre lettres à partir desquelles une IA décompose le langage, puis recompose des mots par probabilité, en fonction de l'environnement de chaque token, puis mot, puis suite de mots. Le tokenizer d'Open Ai permet de montrer comment ses modèles de langage décomposent nos écrits. Jusqu'où peut-on raisonner sur des probabilités plutôt que sur des faits établis ?
Prendre conscience que les productions générées par IA sont des probabilités est essentiel ! Comme lors de l'étape critique des premières réponses, il convient de rappeler les avertissements qui précèdent l'usage des IA génératives : il faut assumer un risque d'erreur ou vérifier par ailleurs.
Le gain de temps envisagé est-il alors si important, quand on ne dispose pas de toutes les connaissances pour effectuer une évaluation critique des productions ? Les IA n'aident-elles pas surtout ceux qui savent déjà ?
Impact environnemental
L'impact énergétique quantifie en Watts/Heure l'énergie consommée par la discussion avec chacune des IA. Elle la convertit en émission de CO² et équivalents
- en durée d'éclairage d'une ampoule LED de 5W
- en durée de consultation de vidéo en ligne.
Des réflexions indispensables pour éduquer à une responsabilité environnementale. Là encore se pose la question de la nécessité de questionner une IA pour accéder à la connaissance. Si besoin, son choix doit prendre en compte son impact environnemental.
Conclusion
La fin de l'activité reprend et formalise les questions posées :
- Les biais induits par le langage.
- Le coût et la rémunération des services : abonnements, données personnelles ?
- Les sources, si le modèle n'est pas pourvu d'un agent conversationnel dédié.
- L'obsolescence potentielle du corpus.
- Des probabilités et non des faits.
- L'impact environnemental.
- La question de la pertinence de l'utilisation d'une IA quand on est au tout début de ses apprentissages.
Compléments
- Avec des élèves plus avancés, il est pertinent de consulter la liste des modèles et leurs détails. On y observe la prédominance des modèles d'origine américaine. On peut solliciter les élèves pour rattacher certains d'entre eux à de grandes entreprises de l'Internet : Google - Alphabet, Meta, Microsoft. On observe la présence de modèles chinois et d'un acteur français, Mistral. La diversité des modèles constatée, on relève également les différences de licences : un début de questionnement des coûts. Les dates de publication de chacun des modèles et leurs itérations établissent aisément la vitesse d'évolution du paysage des modèles : cela invite à un suivi constant.
La sélection des modèles par Compar:IA peut elle-même être questionnée, en regard du nombre des modèles identifiés par Chatbot Arena ou plus encore Hugging Face. En sélectionnant la langue française sur ce dernier, on observe la faible représentation du monde francophone dans les modèles. - Il est intéressant de présenter aux élèves des moteurs de recherche protecteurs de leur vie privée, sans identification ni abonnement, qui intègrent les APIs de certaines itérations d'IA et qui proposent systématiquement un aperçu de leurs sources : Qwant, Brave, DuckDuckGo et son Chat Duck.ai... Ce sont des conditions à respecter si un travail doit leur être proposé.
Il est alors possible de leur demander de comparer les différentes réponses à un même message, en questionnant les sources, d'observer les variations en modifiant un terme de la requête ou en imposant des conditions supplémentaires : format, style, structuration...
Le professeur peut montrer les résultats des IA propriétaires auxquelles il a souscrit, élargissant ainsi le panorama aux IA propriétaires ou à des IA non sélectionnées par Compar:IA. - Dans un autre temps, il est intéressant d'interroger les biais de représentations inhérents aux corpus analysés : la vision du monde proposée par les différentes IA correspondent-elles à sa diversité ? Les opinions représentées sont-elles plurielles ? La nationalité d'un modèle induit-elle des réponses différentes de celles d'un modèle d'une autre nationalité ? Cela correspond-il à des narratifs politiques particuliers ? Qu'en est-il de la représentation des sexes ?
Les fondamentaux
En formant nos élèves aux fondamentaux de toute éducation aux médias, nous leur apprenons bien plus qu'un savoir faire procédurier pour exploiter un outil. Nous les habituons à questionner tous ceux que l'histoire et l'avenir mettront sur leur chemin et construisons leur réelle compétence médiatique.
Travailler sur ces outils d'extraction de données permet aussi de développer les compétences du cadre de référence des compétences numériques (CRCN) évaluées par PIX.
Compar:IA : Consulter